
competition을 진행중에 여러 augmentation기법도 중요하지만 ensemble과 k-fold의 중요성을 다시 한번 깨달았습니다.
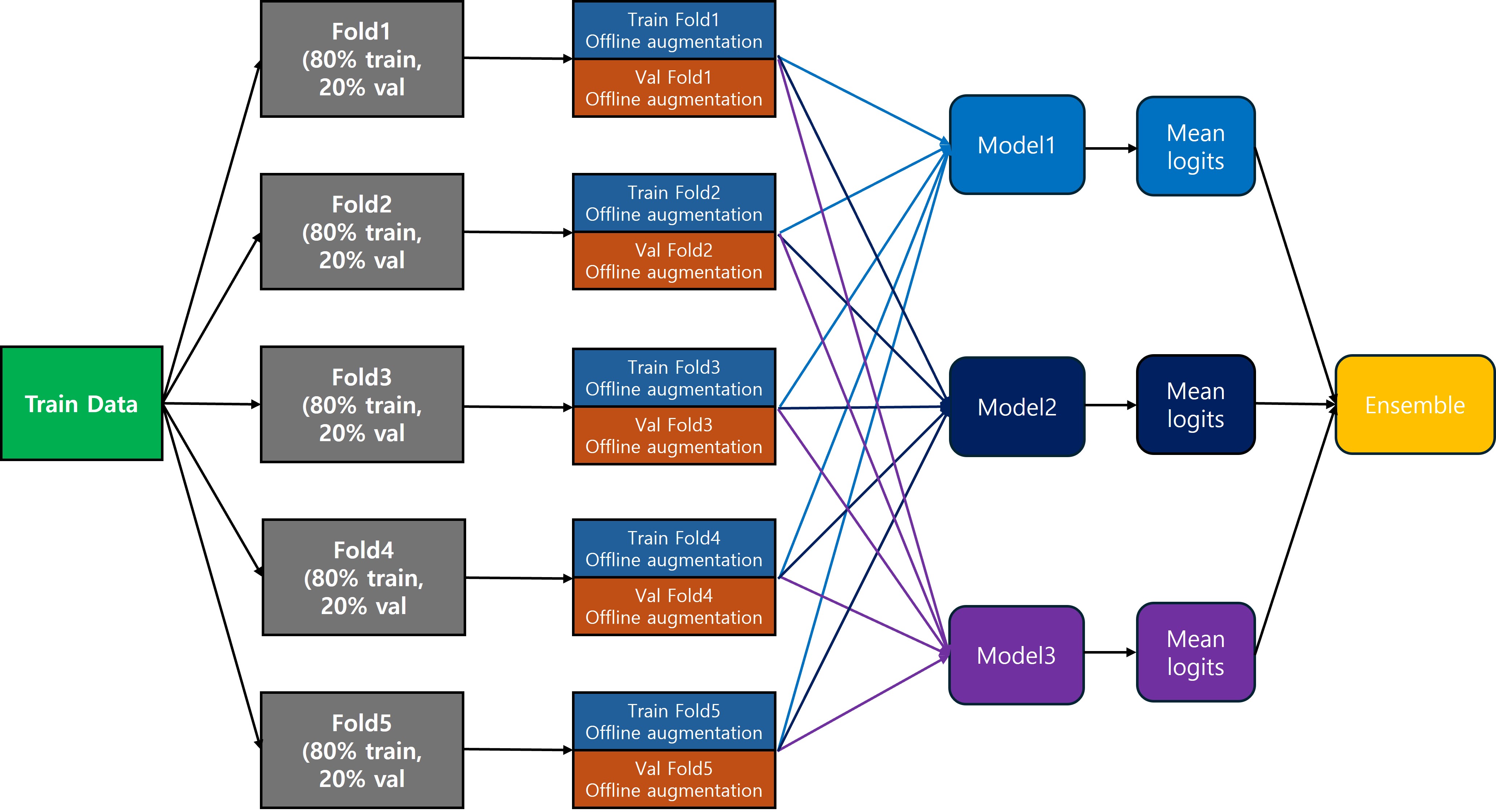
저는 지금까지 위와 같은 형태로 최종 logits값을 구하고 있었습니다.
어디서 검색해서 본게 아닌 스스로 이렇게 하면 되겠구나 하고 사용하고 있었습니다.
Image classification 대회중 여러 아키텍처를 kaggle, dacon에서 찾아보던 중 발견하였습니다.
도배 하자 유형 분류 AI 경진대회에서 public, private 1등한 아키텍처 입니다.

사진과 같이 Fold에서부터 train, valid 비율을 폴드별로 다르게 해서 최대한 모든 데이터를 사용하려고 한 것 같습니다.
fold별로 가장 좋은 성능을 보인 weight를 갖고 ensemble 하였습니다
model은 convnext를 사용하였습니다.

convnext는 convolution layer에 residual 기법을 추가한 것입니다.
model에서는 residual 구조에서만 사용할 수 있는 drop-path 기법을 사용했습니다.


dropout이 랜덤으로 신경망 속 뉴런의 학습을 끊는 것이라면, drop-path는 residual connection 구조에서만 사용할 수 있는 기법으로 랜덤으로 path를 끊는 것입니다.

랜덤한 확률에 따라 f_l(H_{l−1})을 생략하여 output이 f(x) + x 또는 x가 될 수 있습니다.

해당 기법을 사용하면 네트워크 길이가 짧아지므로, 학습시간이 줄어듭니다.
논문에서 실험한 결과로는 0.5로 적용했을 때 학습시간이 25%가 줄어들었고, 성능이 제일 좋았습니다.
0.2로 했을 때는 성능은 Constant Path와 비슷하지만 학습시간이 40% 줄어들었습니다.
dropout과 마찬가지로 서로 다른 모델을 만드는 효과와 비슷하여 ensemble 효과를 가져옵니다.
https://arxiv.org/abs/1603.09382
Deep Networks with Stochastic Depth
Very deep convolutional networks with hundreds of layers have led to significant reductions in error on competitive benchmarks. Although the unmatched expressiveness of the many layers can be highly desirable at test time, training very deep networks comes
arxiv.org
아래는 pytorch lighting으로 작성한 코드입니다.
drop-path와 k-fold + ensemble 코드만 올려봅니다.
import timm
import torch
import torch.nn as nn
class DropPath(nn.Module):
def __init__(self, drop_prob=0.0):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
if self.drop_prob == 0.0 or not self.training:
return x
keep_prob = 1 - self.drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # batch size, 1, 1, 1...
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x / keep_prob * random_tensor
return output
class CustomResNeXt(nn.Module):
def __init__(
self, model_name="resnext50_32x4d", drop_path_rate=0.5, num_classes=500
):
super(CustomResNeXt, self).__init__()
# timm 라이브러리에서 ResNeXt 모델 로드
self.model_name = model_name
self.model = timm.create_model(model_name, pretrained=True)
# classifier head만 학습
for param in self.model.parameters():
param.requires_grad = False
# 마지막 레이어 변경
if model_name == "resnext26ts":
self.model.head.fc = nn.Linear(2048, num_classes)
elif model_name == "resnext50_32x4d":
self.model.fc = nn.Linear(2048, num_classes)
elif model_name == "resnext101_32x16d":
self.model.fc = nn.Linear(2048, num_classes)
else:
raise ValueError("Invalid model name")
# DropPath 추가
self.drop_path = DropPath(drop_prob=drop_path_rate)
# Global Average Pooling 추가
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.model.forward_features(x) # 특징 추출
# DropPath 적용
x = self.drop_path(x)
# Global Pooling을 사용하여 (batch_size, channels, height, width) -> (batch_size, channels, 1, 1)로 변환
x = self.global_pool(x)
# 2D 텐서로 변환 (batch_size, channels)
x = torch.flatten(x, 1)
if self.model_name == "resnext26ts":
self.model.head.fc.requires_grad = True
x = self.model.head.fc(x) # ClassifierHead의 fc 레이어
elif (
self.model_name == "resnext50_32x4d"
or self.model_name == "resnext101_32x16d"
):
self.model.fc.requires_grad = True
x = self.model.fc(x)
else:
raise ValueError("Invalid model name")
return x
timm library에서 불러온 resnext는 drop-path 추가 옵션이 없어서 class를 만들어서 fc layer앞에 추가하였습니다.
import os
from argparse import ArgumentParser
from time import gmtime, strftime
import yaml
import numpy as np
import pandas as pd
import torch
from torch.utils.data import DataLoader
import pytorch_lightning as pl
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
from pytorch_lightning.loggers import CSVLogger, WandbLogger
from sklearn.model_selection import StratifiedKFold
from data_sets import base_dataset
from select_transforms import TransformSelector
from pl_trainer import Sketch_Classifier
from utils.util import dotdict
torch.set_float32_matmul_precision("medium") # 또는 'high'
def load_config(config_file):
with open(config_file, "r") as file:
config = yaml.safe_load(file)
return config
def parse_args(config):
parser = ArgumentParser()
# Set defaults from config file, but allow override via command line
parser.add_argument(
"--exp_name", type=str, default=config.get("exp_name")
) # 현재 실험 이름
parser.add_argument(
"--base_output_dir", type=str, default=config.get("base_output_dir")
) # 실험 결과 저장 폴더
parser.add_argument("--gpus", type=str, default=config.get("gpus"))
parser.add_argument("--batch_size", type=int, default=config.get("batch_size"))
parser.add_argument("--epochs", type=int, default=config.get("epochs"))
parser.add_argument(
"--learning_rate", type=float, default=config.get("learning_rate")
)
parser.add_argument(
"--model_type", type=str, default=config.get("model_type")
) # backbone 타입
parser.add_argument(
"--model_name", type=str, default=config.get("model_name")
) # torchvision, timm을 위한 model 이름
parser.add_argument("--pretrained", type=bool, default=config.get("pretrained"))
parser.add_argument(
"--data_name", type=str, default=config.get("data_name")
) # dataset 이름
parser.add_argument(
"--transform_name", type=str, default=config.get("transform_name")
)
parser.add_argument("--num_classes", type=int, default=config.get("num_classes"))
parser.add_argument("--optim", type=str, default=config.get("optim"))
parser.add_argument("--weight_decay", type=str, default=config.get("weight_decay"))
parser.add_argument("--loss", type=str, default=config.get("loss"))
parser.add_argument(
"--cos_sch", type=int, default=config.get("cos_sch")
) # cos 주기
parser.add_argument("--warm_up", type=int, default=config.get("warm_up"))
parser.add_argument(
"--early_stopping", type=int, default=config.get("early_stopping")
)
parser.add_argument(
"--train_data_dir", type=str, default=config.get("train_data_dir")
)
parser.add_argument(
"--traindata_info_file", type=str, default=config.get("traindata_info_file")
)
parser.add_argument(
"--test_data_dir", type=str, default=config.get("test_data_dir")
)
parser.add_argument(
"--testdata_info_file", type=str, default=config.get("testdata_info_file")
)
parser.add_argument(
"--use_wandb", type=int, default=config.get("use_wandb")
) # wandb 사용?
parser.add_argument(
"--num_workers", type=str, default=config.get("num_workers")
) # dataloader 옵션 관련
parser.add_argument("--cutmix_mixup", type=str, default=config.get("cutmix_mixup"))
parser.add_argument("--kfold_pl_train_return", type=str, default=True)
parser.add_argument("--n_splits", type=int, default=config.get("n_splits"))
parser.add_argument(
"--mixed_precision", type=bool, default=config.get("mixed_precision")
)
parser.add_argument("--cutmix_ratio", type=int, default=config.get("cutmix_ratio"))
parser.add_argument("--mixup_ratio", type=int, default=config.get("mixup_ratio"))
parser.add_argument(
"--accumulate_grad_batches",
type=int,
default=config.get("accumulate_grad_batches"),
),
parser.add_argument(
"--num_cnn_classes", type=int, default=config.get("num_cnn_classes")
) # CNN 분류 클래스 수
return parser.parse_args()
def main(args):
hparams = dotdict(vars(args))
# Stratified K-Fold로 데이터셋 분할
skf = StratifiedKFold(n_splits=hparams.n_splits, shuffle=True, random_state=42)
train_info_df = pd.read_csv(hparams["traindata_info_file"])
transform_selector = TransformSelector(hparams.transform_name)
train_transform = transform_selector.get_transform(True)
test_transform = transform_selector.get_transform(False)
models = []
best_model_paths = [] # 각 폴드의 베스트 모델 가중치 저장
for fold, (train_idx, val_idx) in enumerate(
skf.split(train_info_df, train_info_df["target"])
):
train_df = train_info_df.iloc[train_idx]
val_df = train_info_df.iloc[val_idx]
train_dataset = base_dataset.CustomDataset(
hparams.train_data_dir, train_df, train_transform, False
)
val_dataset = base_dataset.CustomDataset(
hparams.train_data_dir, val_df, test_transform, False
)
train_loader = DataLoader(
train_dataset,
batch_size=hparams.batch_size,
num_workers=hparams.num_workers,
shuffle=True,
pin_memory=True,
drop_last=True,
)
val_loader = DataLoader(
val_dataset,
batch_size=hparams.batch_size,
num_workers=hparams.num_workers,
shuffle=False,
pin_memory=True,
drop_last=True,
)
# 3개의 모델 학습
model_names = ["resnet26ts", "resnext50_32x4d", "resnet101_32x8d"]
best_model_acc = 0
best_model_path = None
for model_name in model_names:
print(f"Training {model_name} on fold {fold}")
if model_name == "resnet101_32x8d":
train_loader = DataLoader(
train_dataset,
batch_size=32,
num_workers=hparams.num_workers,
shuffle=True,
pin_memory=True,
drop_last=True,
)
val_loader = DataLoader(
val_dataset,
batch_size=32,
num_workers=hparams.num_workers,
shuffle=False,
pin_memory=True,
drop_last=True,
)
# 모델 이름을 hparams에 업데이트
hparams.model_name = model_name
# Sketch_Classifier 인스턴스 생성
model = Sketch_Classifier(**hparams)
# logger 설정
csv_logger = CSVLogger(
save_dir=hparams.output_dir + f"/{model_name}/fold{fold}", name="result"
)
my_loggers = [csv_logger]
if hparams.use_wandb:
import wandb
wandb.init(
project="sketch classification",
entity="nav_sketch",
name=f"{model_name}_fold{fold}",
)
wandb_logger = WandbLogger(
save_dir=hparams.output_dir + f"/{model_name}/fold{fold}",
name=os.path.basename(hparams.output_dir),
project="sketch classification",
)
my_loggers.append(wandb_logger)
# ModelCheckpoint 콜백 설정
checkpoint_callback = []
checkpoint_callback.append(
ModelCheckpoint(
dirpath=hparams.output_dir + f"/{model_name}/fold{fold}",
save_last=True,
save_top_k=1,
monitor="val_acc", # val_acc를 기준으로 체크포인트 저장
mode="max",
)
)
if hparams.early_stopping > 0:
early_stop = EarlyStopping(
monitor="valid_loss",
patience=hparams.early_stopping,
verbose=True,
mode="min",
)
checkpoint_callback.append(early_stop)
# Trainer 설정
trainer = pl.Trainer(
logger=my_loggers,
accelerator="cpu" if hparams.gpus == 0 else "gpu",
precision="16-mixed" if hparams.gpus != 0 else 32,
devices=None if hparams.gpus == 0 else hparams.gpus,
callbacks=checkpoint_callback,
max_epochs=hparams.epochs,
accumulate_grad_batches=(
1
if hparams.accumulate_grad_batches <= 0
else hparams.accumulate_grad_batches
),
)
# 학습 진행
trainer.fit(model, train_loader, val_loader)
# 현재 모델이 최고 성능을 기록했는지 확인
if checkpoint_callback[0].best_model_score > best_model_acc:
best_model_acc = checkpoint_callback[0].best_model_score
best_model_path = checkpoint_callback[0].best_model_path
print(f"Best model for fold {fold} is: {best_model_path}")
best_model_paths.append(best_model_path)
# 최종 베스트 모델들로 앙상블 수행
print("Starting ensemble prediction on test dataset")
test_info_df = pd.read_csv(hparams["testdata_info_file"])
test_dataset = base_dataset.CustomDataset(
hparams.test_data_dir, test_info_df, test_transform, True
)
test_loader = DataLoader(
test_dataset,
batch_size=hparams.batch_size,
num_workers=hparams.num_workers,
shuffle=False,
)
test_predictions = np.zeros((len(test_dataset), hparams.num_classes))
for best_model_path in best_model_paths:
model = Sketch_Classifier.load_from_checkpoint(best_model_path)
trainer = pl.Trainer(
accelerator="cpu" if hparams.gpus == 0 else "gpu", devices=hparams.gpus
)
# 모델 예측
predictions = trainer.predict(model, test_loader)
pred_list = []
for batch in predictions:
# 배치의 두 번째 값(2D 배열)을 pred_list에 추가
logits = batch[1] # 두 번째 값만 사용 (torch.Size([64, 500]))
pred_list.append(logits.cpu().numpy())
# 모든 배치의 예측값을 합침
pred_list = np.concatenate(pred_list, axis=0)
# test_predictions에 예측값을 더함
test_predictions += pred_list
# 모델 수로 나누어 평균을 냄
test_predictions /= len(best_model_paths)
output_df = pd.DataFrame()
output_df["ID"] = range(len(test_info_df))
output_df["image_path"] = test_info_df["image_path"]
output_df["target"] = test_predictions.argmax(axis=1)
if not os.path.isdir(args.output_dir):
os.makedirs(args.output_dir)
output_df.to_csv(os.path.join(args.output_dir, "output.csv"), index=False)
if __name__ == "__main__":
pl.seed_everything(42)
# ------------
# args
# ------------
config = load_config("config2.yaml")
args = parse_args(config)
## output_dir
current_time = strftime("%m-%d_0", gmtime())
pt = "O" if args.pretrained else "X"
name_str = (
f"{args.model_name}-{args.batch_size}-{args.learning_rate}"
+ f"-{args.optim}-{pt}-{args.exp_name}"
)
# args.output_dir = os.path.join(args.base_output_dir, args.exp_name + "_" + current_time)
args.output_dir = os.path.join(args.base_output_dir, name_str + "_" + current_time)
if os.path.isdir(args.output_dir):
while True:
cur_exp_number = int(args.output_dir[-2:].replace("_", ""))
args.output_dir = args.output_dir[:-2] + "_{}".format(cur_exp_number + 1)
if not os.path.isdir(args.output_dir):
break
# gpus
args.gpus = [int(i) for i in str(args.gpus).split(",")]
main(args)
k-fold에서 train, valid 비율은 8:2로 가져갔습니다